date grupate sunt cele care, obținute dintr-un studiu, nu sunt încă organizate pe clase. Când este un număr gestionabil de date, de obicei 20 sau mai puțin, și există puține date diferite, acestea pot fi tratate ca informații negroupate și valoroase extrase din acesta.
Datele care nu sunt grupate provin din sondaj sau din studiul efectuat pentru a le obține și, prin urmare, nu au prelucrare. Să vedem câteva exemple:

-Rezultatele unui test de IQ pe 20 de studenți aleatori de la o universitate. Datele obținute au fost următoarele:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112.106
-Vârstele a 20 de angajați ai unei anumite cafenele populare:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
-Nota finală medie de 10 elevi la o clasă de matematică:
3.2; 3.1; 2.4; 4.0; 3,5; 3,0; 3,5; 3,8; 4.2; 4.9
Indice articol
Există trei proprietăți importante care caracterizează un set de date statistice, indiferent dacă sunt sau nu grupate, care sunt:
-Poziţie, care este tendința datelor de a se grupa în jurul anumitor valori.
-Dispersie, o indicație a cât de împrăștiate sau împrăștiate sunt datele în jurul unei valori date.
-Formă, Se referă la modul în care sunt distribuite datele, care este apreciat atunci când este construit un grafic al acestora. Există curbe foarte simetrice și, de asemenea, înclinate, fie la stânga, fie la dreapta unei anumite valori centrale.
Pentru fiecare dintre aceste proprietăți există o serie de măsuri care le descriu. Odată obținute, acestea ne oferă o imagine de ansamblu asupra comportamentului datelor:
-Cele mai utilizate măsuri de poziție sunt media aritmetică sau pur și simplu media, mediana și modul.
-Intervalul, varianța și abaterea standard sunt frecvent utilizate în dispersie, dar nu sunt singurele măsuri de dispersie..
-Și pentru a determina forma, media și mediana sunt comparate prin părtinire, așa cum veți vedea în scurt timp.
-Media aritmetică, cunoscut și ca medie și notat ca X, se calculează după cum urmează:
X = (x1 + XDouă + X3 +… Xn) / n
Unde x1, XDouă,…. Xn, sunt datele și n este totalul acestora. În notație de însumare avem:
-Median este valoarea care apare în mijlocul unei secvențe ordonate de date, așa că, pentru a le obține, este necesar să comandăm datele în primul rând.
Dacă numărul de observații este impar, nu există nicio problemă în găsirea punctului de mijloc al setului, dar dacă avem un număr par de date, cele două date centrale sunt căutate și mediate.
-Modă este cea mai comună valoare observată în setul de date. Nu există întotdeauna, deoarece este posibil ca nicio valoare să nu se repete mai frecvent decât alta. Ar putea exista și două date cu o frecvență egală, caz în care vorbim de o distribuție bi-modală.
Spre deosebire de cele două măsuri anterioare, modul poate fi utilizat cu date calitative.
Să vedem cum sunt calculate aceste măsuri de poziție cu un exemplu:
Să presupunem că dorim să determinăm media aritmetică, mediana și modul în exemplul propus la început: vârstele de 20 de angajați ai unei cafenele:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
jumătate se calculează pur și simplu adăugând toate valorile și împărțind la n = 20, care este numărul total de date. În acest fel:
X = (24 + 20 + 22 + 19 + 18 + 27+ 25 + 19 + 27 + 18 + 21 + 22 + 23 + 21+ 19 + 22 + 27+ 29 + 23+ 20) / 20 =
= 22,3 ani.
Pentru a găsi median mai întâi trebuie să sortați setul de date:
18, 18, 19, 19, 19, 20, 20, 21, 21, 22, 22, 22, 23, 23, 24, 25, 27, 27, 27, 29
Deoarece este un număr par de date, cele două date centrale, evidențiate cu caractere aldine, sunt luate și mediate. Deoarece ambii au 22 de ani, mediana este de 22 de ani.
În cele din urmă, Modă Datele se repetă cel mai mult sau cel a cărui frecvență este mai mare, acesta fiind de 22 de ani.
Gama este pur și simplu diferența dintre cea mai mare și cea mai mică dintre date și vă permite să apreciați rapid variabilitatea datelor. Dar, în afară de aceasta, există și alte măsuri de dispersie care oferă mai multe informații despre distribuția datelor..
Varianța este notată ca s și se calculează prin expresia:
Deci, pentru a interpreta corect rezultatele, abaterea standard este definită ca rădăcina pătrată a varianței sau, de asemenea, abaterea cvasi-standard, care este rădăcina pătrată a cvasivarianței:
Este o comparație între media X și mediana Med:
-Dacă Med = medie X: datele sunt simetrice.
-Când X> Med: înclină spre dreapta.
-Și dacă X < Med: los datos sesgan hacia la izquierda.
Găsiți media, mediana, modul, intervalul, varianța, abaterea standard și părtinirea pentru rezultatele unui test de IQ efectuat la 20 de studenți dintr-o universitate:
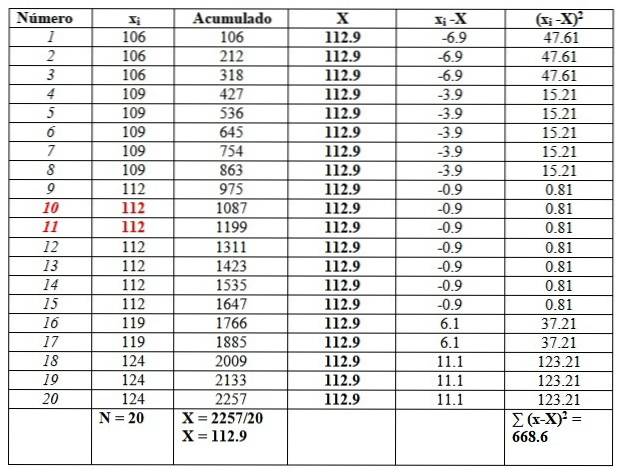
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112, 106
Vom comanda datele, deoarece va fi necesar să găsim mediana.
106, 106, 106, 109, 109, 109, 109, 109, 112, 112, 112, 112, 112, 112, 112, 119, 119, 124, 124, 124
Și le vom pune într-un tabel după cum urmează, pentru a facilita calculele. A doua coloană intitulată „Acumulat” este suma datelor corespunzătoare plus cea anterioară..
Această coloană vă va ajuta să găsiți cu ușurință media, împărțind ultima acumulată la numărul total de date, așa cum se vede la sfârșitul coloanei „Acumulat”:
X = 112,9
Mediana este media datelor centrale evidențiate cu roșu: numărul 10 și numărul 11. Deoarece sunt aceleași, mediana este 112.
În cele din urmă, modul este valoarea care se repetă cel mai mult și este 112, cu 7 repetări..
În ceea ce privește măsurile de dispersie, intervalul este:
124-106 = 18.
Varianța se obține împărțind rezultatul final în coloana din dreapta la n:
s = 668,6 / 20 = 33,42
În acest caz, abaterea standard este rădăcina pătrată a varianței: √33.42 = 5.8.
Pe de altă parte, valorile cvasivarianței și cvasi-deviației standard sunt:
sc= 668,6 / 19 = 35,2
Abaterea cvasi-standard = √35.2 = 5.9
În cele din urmă, tendința este ușor spre dreapta, deoarece media 112,9 este mai mare decât mediana 112.



Nimeni nu a comentat acest articol încă.